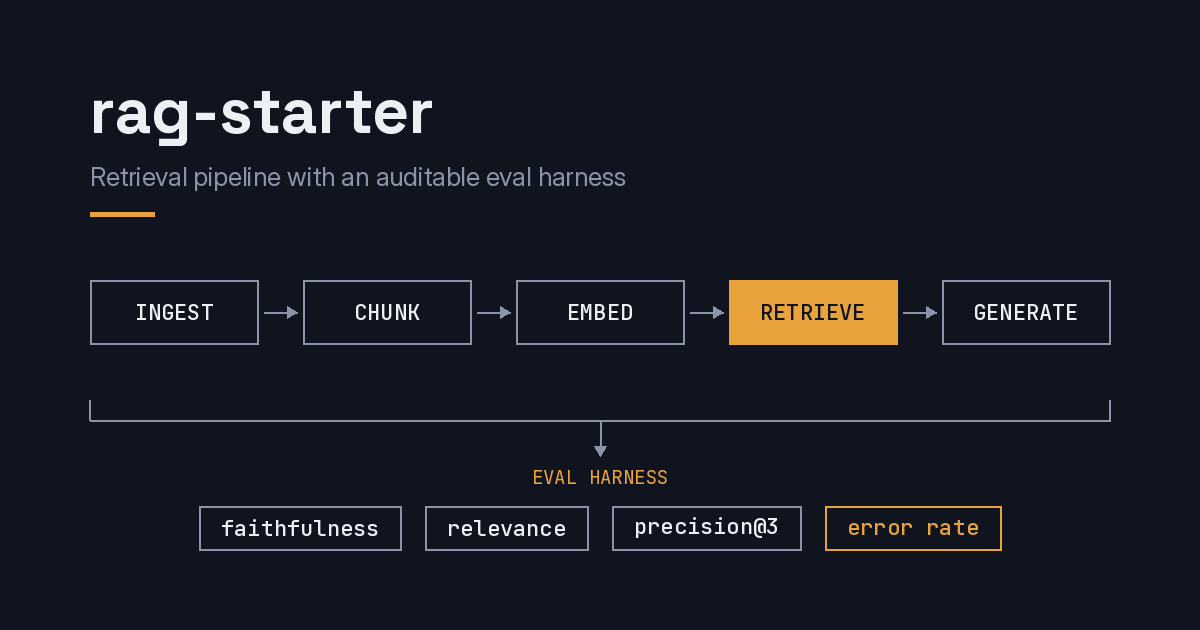
RAG Starter
A production-patterned RAG pipeline with a full evaluation harness: faithfulness, relevance, and Precision@3 scoring, error rate as a first-class metric, and end-to-end Langfuse tracing.
A production-patterned RAG pipeline with a full evaluation harness: faithfulness, relevance, and Precision@3 scoring, error rate as a first-class metric, and end-to-end Langfuse tracing.

Adding strict typing to my eval harness exposed an intermittent judge failure, and fixing that exposed a second bug a passing eval had been hiding. The lesson: a green eval is not a correct eval.
I made my RAG project production-ready by reading the Anthropic Python SDK end to end and stealing four patterns from it. Here is what each one was and why it mattered.