RAG Starter is a retrieval-augmented generation pipeline built the way I’d ship one to a client: typed end to end, observable end to end, and benchmarked against an auditable evaluation dataset that lives in the repo.
Source: github.com/digitalrower/rag-starter
What it does
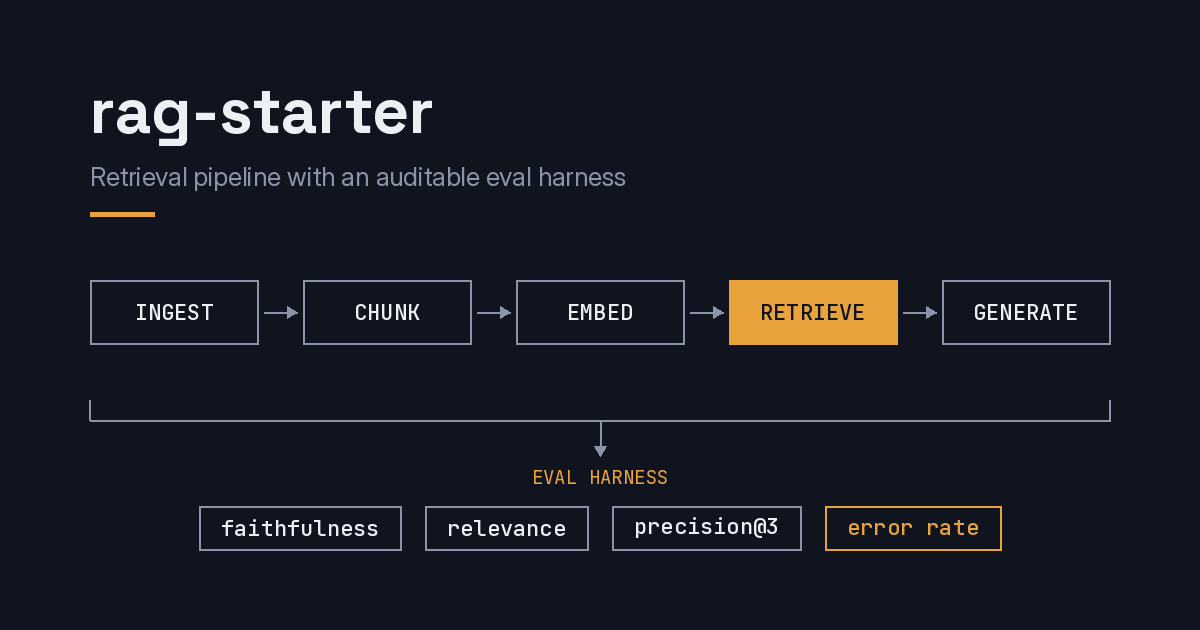
Documents are ingested, chunked, embedded, and stored in ChromaDB. At query time the pipeline retrieves the top-ranked chunks, grounds a Claude response in them, and traces the full request through Langfuse, retrieval, generation, and scoring included.
Evaluation methodology
The part most RAG demos skip is the part this project is built around. Every pipeline change is measured against a fixed eval set with an LLM-as-judge harness (Claude Haiku, temperature 0, structured JSON output) across three quality scorers:
- Faithfulness. Is the answer grounded in the retrieved context, or is the model improvising?
- Relevance. Does the answer actually address the question asked?
- Precision@3. Of the top three retrieved chunks, how many are genuinely relevant?
Error rate is tracked as its own first-class metric, not folded into the quality averages. Errored eval items are excluded from quality scoring entirely. Counting a failed request as a zero-quality answer conflates reliability failures with quality measurement and corrupts comparability between runs. Separating the two means a retry-config change and a prompt change can each be judged on the axis they actually affect.
Results
| Metric | Baseline | Current |
|---|---|---|
| Faithfulness | [X.X] | [X.X] |
| Relevance | [X.X] | [X.X] |
| Precision@3 | [X.X] | [X.X] |
| Error rate | [X.X%] | [X.X%] |
The eval dataset, run outputs (results.json, summary.json), and scoring code are all committed to the repo, so every number above can be reproduced and audited.
Production patterns
Three patterns carry most of the production weight:
Centralized client factory. A single configured Anthropic client with retry behavior set in one place. The SDK already implements exponential backoff with jitter; the work is configuring and centralizing it, not rebuilding it.
Typed boundaries. Pydantic models at every data boundary (models.py), so malformed scorer output or a partial retrieval fails loudly at the edge instead of silently corrupting results downstream.
Typed error hierarchy. A dedicated exception hierarchy (errors.py) so callers can distinguish a retryable API failure from a data problem from a bug, and the eval runner can classify failures correctly into the error-rate metric.
Observability
Every query produces a Langfuse trace covering retrieval, generation, and scoring, with eval scores attached directly to traces via score configs. Regressions show up in the dashboard with the trace that caused them one click away.
Stack
Python, ChromaDB, Anthropic API, Langfuse, ruff and mypy in CI.